
Google在2024年02月21日正式推出了首个开源模型族Gemma,并同时上架了2b和7b两个版本。您可以使用函数计算的GPU实例以及函数计算的闲置模式低成本快速部署Gemma模型服务。
前提条件
已开通函数计算服务,详情请参见快速创建函数。
已创建命名空间和镜像仓库,详情请参见创建命名空间和创建镜像仓库。
操作步骤
部署Gemma模型服务的过程中将产生部分费用,包括GPU资源使用、vCPU资源使用、内存资源使用、磁盘资源使用和公网出流量以及函数调用的费用。具体信息,请参见费用说明。
创建应用
下载Gemma模型权重。您可以选择从Hugging Face或ModelScope平台下载,本文以从ModelScope下载Gemma-2b-it模型为例,详情请参见Gemma-2b-it。
重要如果您使用Git下载模型,请先安装Git扩展LFS后,执行
git lfs install初始化Git LFS,然后再执行git clone进行下载。否则,由于模型过大,可能导致下载的模型不完整,无法正常使用Gemma服务。创建Dockerfile文档和模型服务代码文件
app.py。Dockerfile
FROM registry-vpc.cn-shanghai.aliyuncs.com/modelscope-repo/modelscope:fc-deploy-common-v17 WORKDIR /usr/src/app COPY . . RUN pip install -U transformers CMD [ "python3", "-u", "/usr/src/app/app.py" ] EXPOSE 9000app.py
from flask import Flask, request from transformers import AutoTokenizer, AutoModelForCausalLM model_dir = '/usr/src/app/gemma-2b-it' app = Flask(__name__) tokenizer = AutoTokenizer.from_pretrained(model_dir) model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto") @app.route('/invoke', methods=['POST']) def invoke(): request_id = request.headers.get("x-fc-request-id", "") print("FC Invoke Start RequestId: " + request_id) text = request.get_data().decode("utf-8") print(text) input_ids = tokenizer(text, return_tensors="pt").to("cuda") outputs = model.generate(**input_ids, max_new_tokens=1000) response = tokenizer.decode(outputs[0]) print("FC Invoke End RequestId: " + request_id) return str(response) + "\n" if __name__ == '__main__': app.run(debug=False, host='0.0.0.0', port=9000)关于函数计算支持的所有HTTP Header,请参见函数计算公共请求头。
完成后代码目录结构如下所示。
. |-- app.py |-- Dockerfile `-- gemma-2b-it |-- config.json |-- generation_config.json |-- model-00001-of-00002.safetensors |-- model-00002-of-00002.safetensors |-- model.safetensors.index.json |-- README.md |-- special_tokens_map.json |-- tokenizer_config.json |-- tokenizer.json `-- tokenizer.model 1 directory, 12 files依次执行以下命令构建并推送镜像。
IMAGE_NAME=registry.cn-shanghai.aliyuncs.com/{NAMESPACE}/{REPO}:gemma-2b-it docker login --username=mu****@test.aliyunid.com registry.cn-shanghai.aliyuncs.com docker build -f Dockerfile -t $IMAGE_NAME . && docker push $IMAGE_NAME以上命令中的{NAMESPACE}和{REPO}需替换为您已创建的命名空间名称和镜像仓库名称。
创建函数。
登录函数计算控制台,在左侧导航栏,选择函数。
在顶部菜单栏,选择地域,然后在函数页面单击创建函数。
在创建函数页面,选择使用容器镜像方式,设置以下配置项,然后单击创建。
重点配置项说明如下,其余配置项选择默认值即可。
配置项
说明
镜像配置
镜像选择方式
选择使用 ACR 中的镜像。
容器镜像
单击下方的选择 ACR 中的镜像,然后在选择容器镜像面板,选择步骤3推送的镜像。
监听端口
设置为9000。
高级配置
是否使用GPU
选择使用GPU。
GPU 卡型
选择Tesla 系列 T4 卡型。
规格方案
GPU显存规格设置为16 GB。
vCPU 规格设置为2核。
内存规格设置为16 GB。
待上一步创建的函数的状态变更为函数已激活时,您可以为其开启闲置预留模式。

在函数详情页面选择配置页签,在左侧导航栏,选择预留实例,然后单击创建预留实例数策略。
在创建预留实例数策略面板中,版本或别名选择LATEST,预留实例数设置为1,闲置模式选择启用,然后单击确定。
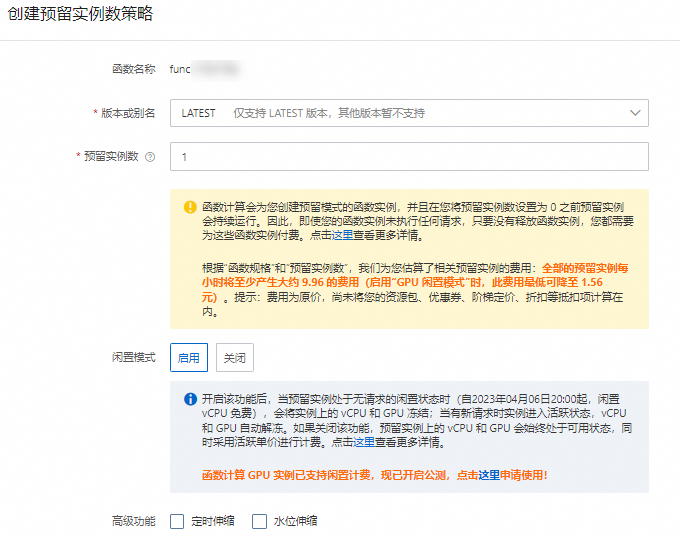
待当前预留实例数变更为1,且您可以看到已开启闲置模式的字样,表示GPU闲置预留实例已成功启动。

使用Google Gemma服务
在函数详情页面,选择配置页签,然后在左侧导航栏,选择触发器,在触发器页面获取触发器的URL。
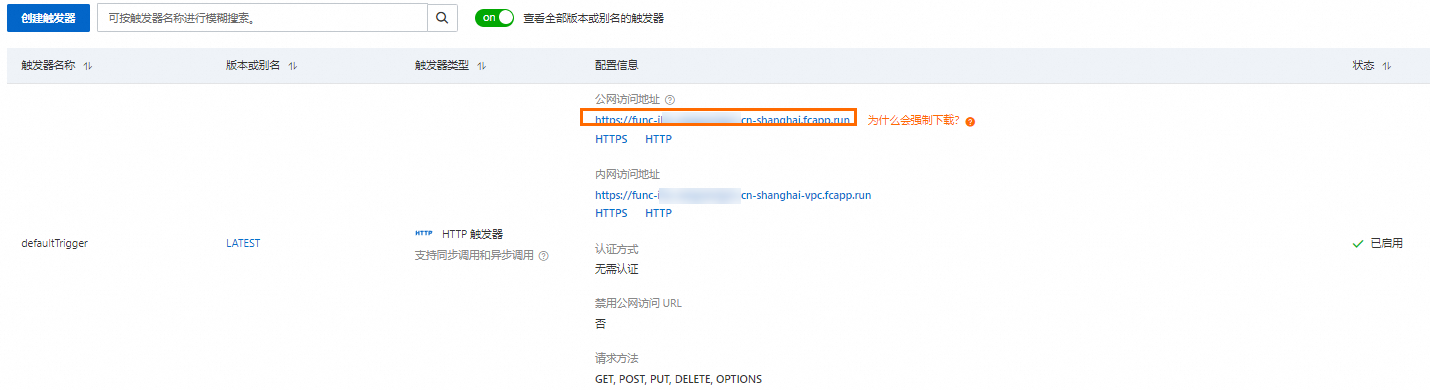
执行以下命令调用函数。
curl -X POST -d "who are you" https://func-i****-****.cn-shanghai.fcapp.run/invoke预期输出如下。
<bos>who are you? I am a large language model, trained by Google. I am a conversational AI that can understand and generate human language, and I am able to communicate and provide information in a comprehensive and informative way. What can I do for you today?<eos>在函数详情页面,选择实例页签,在实例页面单击目标实例ID右侧操作列的实例指标,在实例详情页面的实例指标页签查看指标情况。
您可以看到在没有函数调用发生时,该实例的显存使用量会降至零。而当有新的函数调用请求到来时,函数计算平台会迅速恢复并分配所需的显存资源。从而达到降本效果。
说明查看指标的实例,需要先启用日志功能,具体请参见配置日志。

函数调用结束后,函数计算会自动将GPU实例置为闲置模式,您无需手动操作。在下次调用到来之前,函数计算将该实例唤醒,置为活跃模式进行服务。
删除资源
如您暂时不需要使用此函数,请及时删除对应资源。如果您需要长期使用此应用,请忽略此步骤。
返回函数计算控制台概览页面,在左侧导航栏,单击函数。
单击目标函数右侧操作列的,在弹出的对话框中,勾选我确认要删除以上资源,并同时删除此函数。我已知晓这些资源删除后将无法找回,然后单击删除函数。
费用说明
套餐领取
为了方便您体验本文提供的应用,首次开通用户可以领取试用套餐并开通函数计算服务。更多信息,请参见试用额度。试用套餐不支持抵扣磁盘使用量的费用,超出512 MB的磁盘使用量将按量付费。
资源消耗评估
函数计算配置vCPU为2核、内存为16 GB、GPU显存为16 GB、磁盘大小为512 MB。1个闲置预留实例使用1小时,通过多次与Google Gemma进行对话,1小时内累计的活跃函数时间为20分钟。产生的资源计费可参考以下表格内容:
计费项 | 活跃时间(20分钟)计费 | 闲置时间(40分钟)计费 | |
vCPU资源 |
|
| |
内存资源 |
|
| |
GPU资源 |
|
| |
更多关于函数计算的计费信息,请参见计费概述。
相关文档
关于Google发布的开源模型族Gemma的更多详情,请参见gemma-open-models。
关于GPU实例闲置模式计费详情以及计费示例,请参见计费概述。